Retry Timeout Pattern : Build Resilient, Cloud-Native Systems
Introduction: Why “Just Retry” Is Dangerous
In distributed systems, failures are often temporary—a brief network hiccup, a slow dependency, a momentary spike. Retrying can help…
But blind retries without limits can turn a small glitch into a full outage.
That’s why Retry must always be paired with Timeouts and Backoff.
Introduction: Why “Just Retry” Is Dangerous
In distributed systems, failures are often temporary—a brief network hiccup, a slow dependency, a momentary spike. Retrying can help…
But blind retries without limits can turn a small glitch into a full outage.
That’s why Retry must always be paired with Timeouts and Backoff.
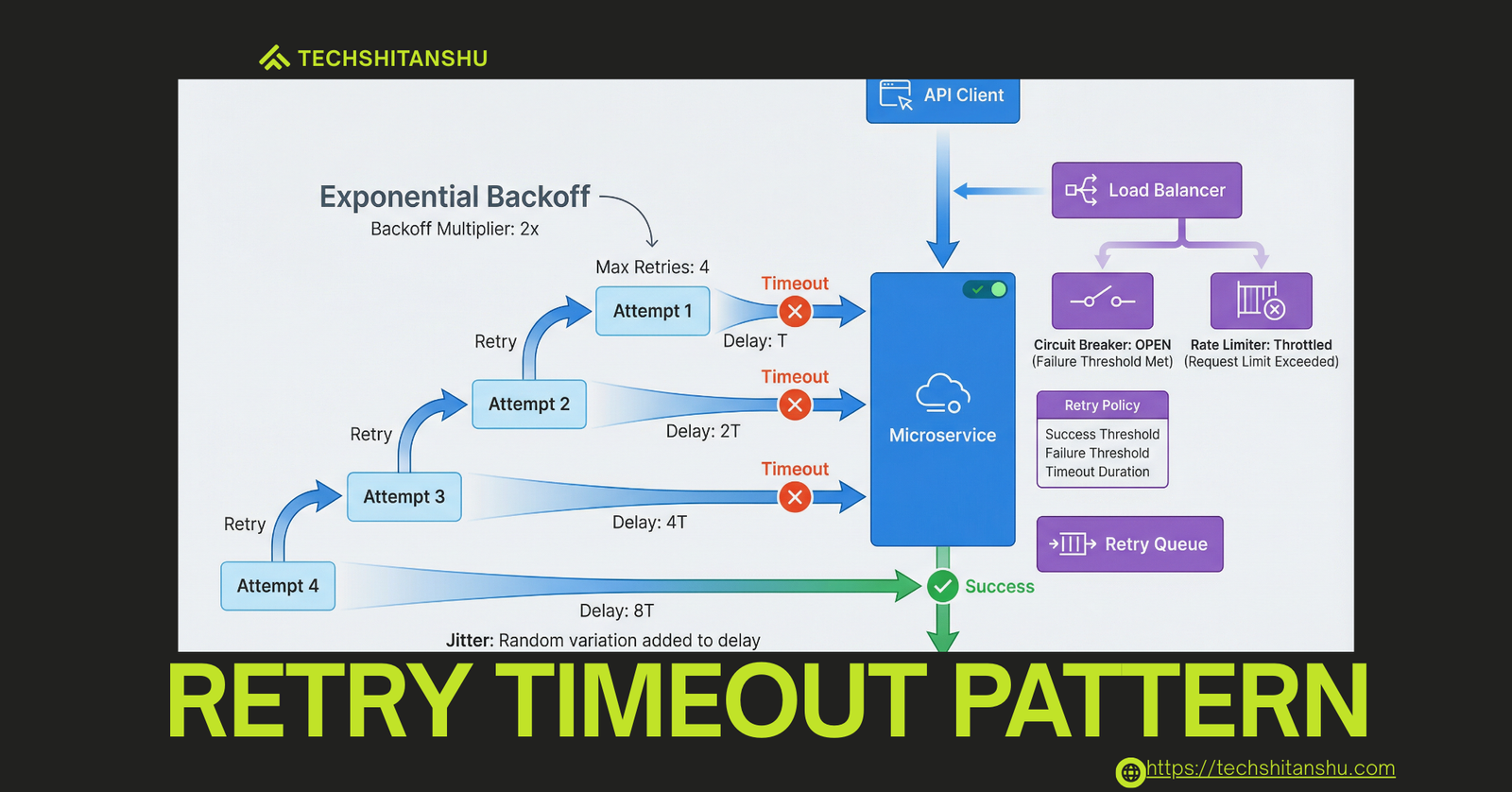
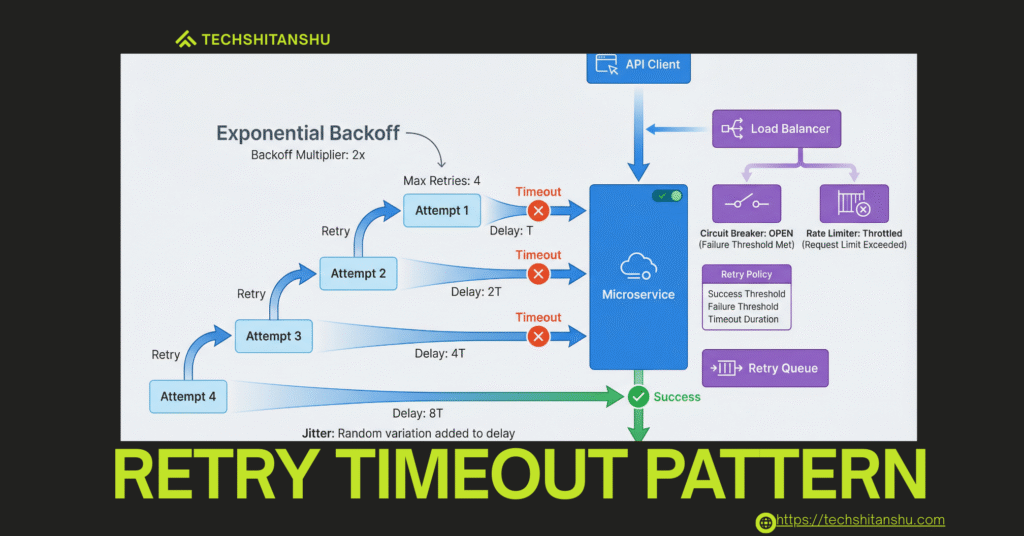
What Is the Retry Timeout Pattern?
Retry Pattern: Reattempt a failed operation when the failure is likely transient.
Timeout Pattern: Stop waiting after a defined period to avoid resource exhaustion.
Backoff: Gradually increase the delay between retries to reduce pressure on dependencies.
Together, they form a defensive shield for modern APIs.
Why Enterprises Care
This pattern directly impacts:
API reliability & SLAs
Cloud cost control
Customer experience
Incident reduction
It attracts premium ads from:
Cloud platforms
Observability tools
DevOps tooling
Security & SRE solutions
The Core Problem This Pattern Solves
Without control:
Requests pile up
Threads block
Dependencies melt down
Cascading failures spread
Retry + Timeout + Backoff keeps the system responsive and self-healing.
Architecture Overview
Client → Service A
|
|-- Timeout (e.g., 2s)
|-- Retry (max 3 attempts)
|-- Backoff (100ms → 300ms → 900ms)
|
External Service
Each call:
Has a deadline
Retries are limited
Pressure decreases over time
Types of Backoff Strategies
1️⃣ Fixed Backoff
Same delay every retry.
✔️ Simple
❌ Can still overload systems
2️⃣ Exponential Backoff (Recommended)
Delay increases exponentially.
✔️ Reduces load
✔️ Industry standard
3️⃣ Exponential Backoff with Jitter (Best Practice)
Adds randomness to avoid retry storms.
✔️ Used by AWS, Google, Netflix
Real-World Example: Payment API Timeout
Problem:
Payment gateway slows down → checkout freezes.
Solution:
Timeout: 2 seconds
Retry: 3 attempts
Backoff: exponential + jitter
Result:
✔️ Checkout stays responsive
✔️ Failed payments don’t block users
Retry & Timeout vs Circuit Breaker
| Pattern | Purpose |
|---|---|
| Retry | Handle transient failures |
| Timeout | Prevent waiting forever |
| Circuit Breaker | Stop calling a failing service |
👉 Best practice: Use all three together.
Benefits
✅ Prevents thread exhaustion
✅ Improves user experience
✅ Reduces cascading failures
✅ Controls cloud costs
✅ Boosts system reliability
Common Use Cases
✔️ External APIs
✔️ Payment gateways
✔️ Authentication services
✔️ Message brokers
✔️ Cloud service calls
Common Mistakes to Avoid
❌ Infinite retries
❌ No timeouts
❌ Retrying non-idempotent operations
❌ Same retry timing for all clients
Best Practices Checklist
✔️ Always set timeouts
✔️ Limit retry attempts
✔️ Use exponential backoff + jitter
✔️ Retry only transient errors
✔️ Combine with circuit breakers
✔️ Monitor retry rates
Works seamlessly with:
Kubernetes
API Gateways
Service Mesh (Istio, Linkerd)
Resilience4j
AWS SDKs
FAQs
Q: Should I retry every failure?
No. Retry only transient errors like timeouts or 5xx responses.
Q: Why is timeout mandatory with retries?
Without timeouts, retries block resources indefinitely.
Q: What’s the best backoff strategy?
Exponential backoff with jitter.
Q: Is this pattern needed in Kubernetes?
Yes. Infrastructure retries don’t replace application-level control.
Q: Can retries increase latency?
Yes—but controlled retries are better than system outages.
Final Thoughts
Retries are powerful.
Uncontrolled retries are dangerous.The Retry & Timeout Pattern (with Backoff) ensures your system:
Fails gracefully
Recovers intelligently
Scales safely
In modern systems, resilience is designed—not hoped for.
“This is part of our complete Microservices Design Patterns Series.”

Leave a Reply