Database Per Service Pattern: The Smart Way to Build Scalable Microservices
Introduction: Why Databases Break Microservices
When teams first move to microservices, they usually split code correctly — but they forget one thing:
👉 The database.
Many systems fail because multiple services still share a single database. This creates:
Tight coupling
Deployment nightmares
Scaling limitations
Hidden dependencies
The Database per Service Pattern solves this problem at its core.
It’s one of the most critical microservices design patterns, especially for enterprise systems, SaaS platforms, fintech apps, and cloud-native architectures.
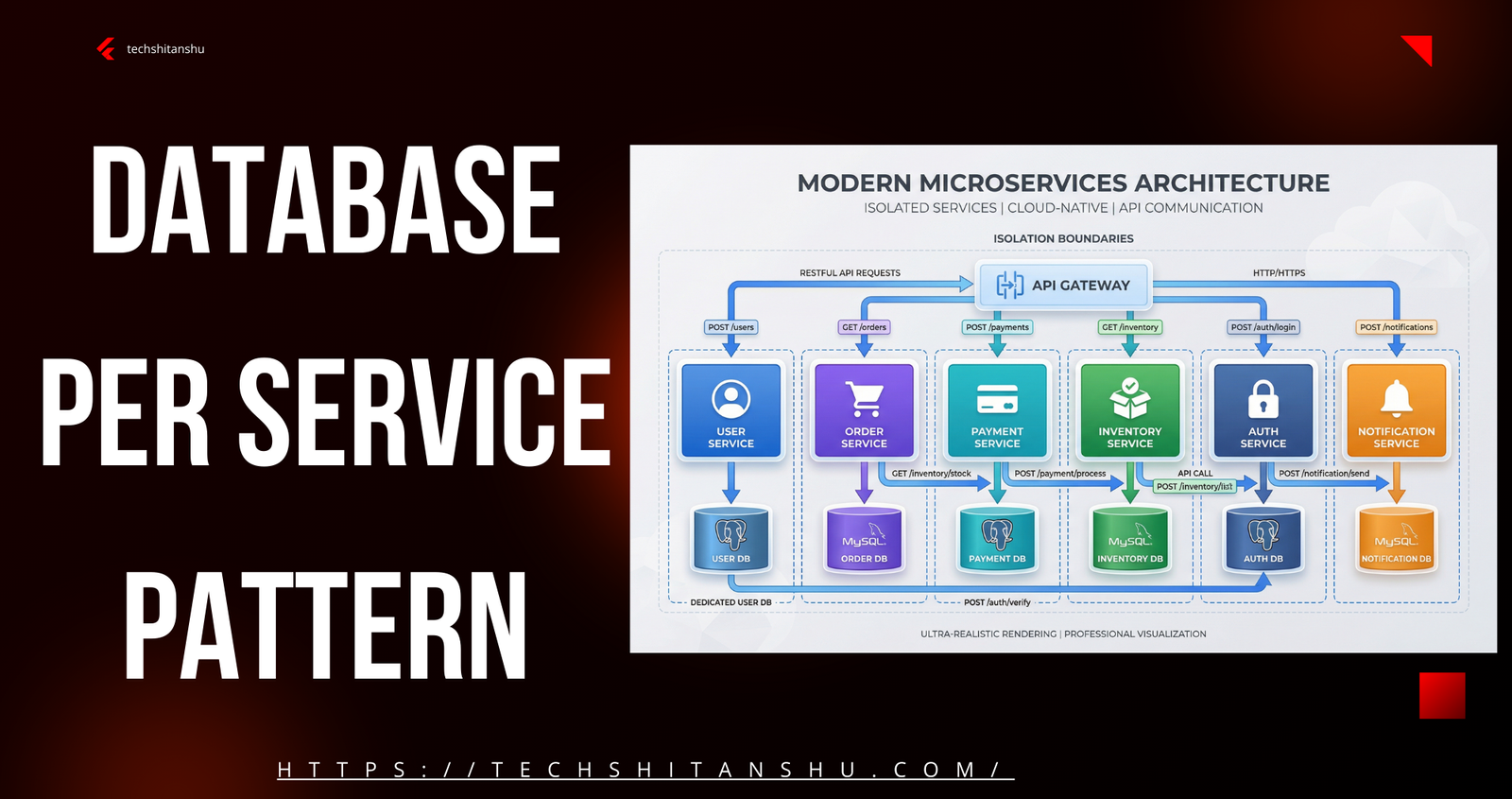
What Is the Database per Service Pattern?
The Database per Service Pattern states:
Each microservice owns its own database, schema, and data model — and no other service can access it directly.
Key Rule
🚫 No shared database tables
🚫 No cross-service joins
🚫 No direct database access between services
Instead:
✅ Services communicate only via APIs or events
Why Shared Databases Are Dangerous in Microservices
Let’s be honest — shared databases feel convenient at first.
But over time, they cause serious issues:
| Problem | Impact |
|---|---|
| Tight coupling | One change breaks many services |
| Slow deployments | DB migrations block teams |
| Scaling issues | One DB becomes a bottleneck |
| Security risks | Overexposed sensitive data |
| Ownership confusion | Nobody “owns” the data |
This is exactly what microservices are meant to avoid.
How Database per Service Pattern Works
Each microservice:
Has its own database
Controls its schema
Chooses its database technology
Manages its data lifecycle
Example Architecture
User Service → PostgreSQL
Order Service → MySQL
Payment Service → DynamoDB
Analytics Service → MongoDB
Different databases. Different schemas. Full isolation.
Why This Pattern Is So Powerful (Benefits)
1️⃣ Loose Coupling (Biggest Win)
Services evolve independently — no accidental breakage.
2️⃣ Independent Scaling
Hot service? Scale only its database.
Cold service? Don’t waste resources.
3️⃣ Technology Freedom
Each service uses the best database for its job:
SQL for transactions
NoSQL for flexibility
Time-series DBs for metrics
4️⃣ Faster Deployments
Database changes don’t block other teams.
5️⃣ Stronger Security
Clear data boundaries reduce blast radius.
Real-World Use Case Example
E-commerce Platform
| Service | Database | Reason |
|---|---|---|
| Catalog | MongoDB | Flexible product schema |
| Orders | PostgreSQL | Strong transactions |
| Payments | DynamoDB | High availability |
| Reviews | Elasticsearch | Fast search |
Each team moves fast — without stepping on each other.
The Hard Truth: Challenges You Must Handle
This pattern is powerful — but not free.
❌ No Cross-Database Joins
You must redesign queries and data access.
❌ Data Consistency Is Hard
Traditional ACID transactions don’t work across services.
❌ Reporting Gets Complex
Analytics needs event streams or data lakes.
How to Handle Data Consistency
✅ Use Event-Driven Architecture
Services publish events like:
OrderCreatedPaymentCompleted
Other services react asynchronously.
✅ Use Saga Pattern
For long-running business transactions:
Orchestration Saga
Choreography Saga
👉 Database per Service + Saga Pattern is a common enterprise combo.
Querying Data Across Services (Without Breaking Rules)
Instead of database joins, use:
🔹 API Composition
API Gateway or BFF aggregates responses.
🔹 CQRS Pattern
Separate:
Write models (per service DB)
Read models (optimized views)
🔹 Event-Driven Read Models
Build reporting databases from event streams.
Best Practices (Enterprise-Ready)
✔️ Never share databases
✔️ Enforce ownership boundaries
✔️ Use schema versioning
✔️ Automate database migrations
✔️ Monitor data drift
✔️ Document service contracts
When NOT to Use This Pattern
Avoid it when:
You’re building a small monolith
Team size is very small
Operational maturity is low
This pattern shines in mid to large-scale systems.
Database per Service vs Shared Database
| Feature | Shared DB | Database per Service |
|---|---|---|
| Coupling | High | Low |
| Scalability | Limited | High |
| Team autonomy | Low | High |
| Security | Weak | Strong |
| Cloud readiness | Poor | Excellent |
Cloud & DevOps Alignment
This pattern works perfectly with:
Kubernetes
Docker
AWS / Azure / GCP
CI/CD pipelines
Zero-downtime deployments
FAQs
❓ Is Database per Service mandatory in microservices?
Yes — it’s a core principle for true microservice independence.
❓ Can two services share a read-only database?
No. Even read-only access creates hidden coupling.
❓ How do I run reports across services?
Use event streams, data warehouses, or CQRS read models.
❓ Does this increase infrastructure cost?
Initially yes — but it reduces long-term failure costs.
❓ Can each service use a different database type?
Yes — that’s one of the biggest advantages.
Final Thoughts
The Database per Service Pattern isn’t optional if you want:
True scalability
Independent teams
Cloud-native resilience
It’s not the easiest path — but it’s the right one for serious systems.
“Part of our Microservices Design Patterns Series.”

Leave a Reply