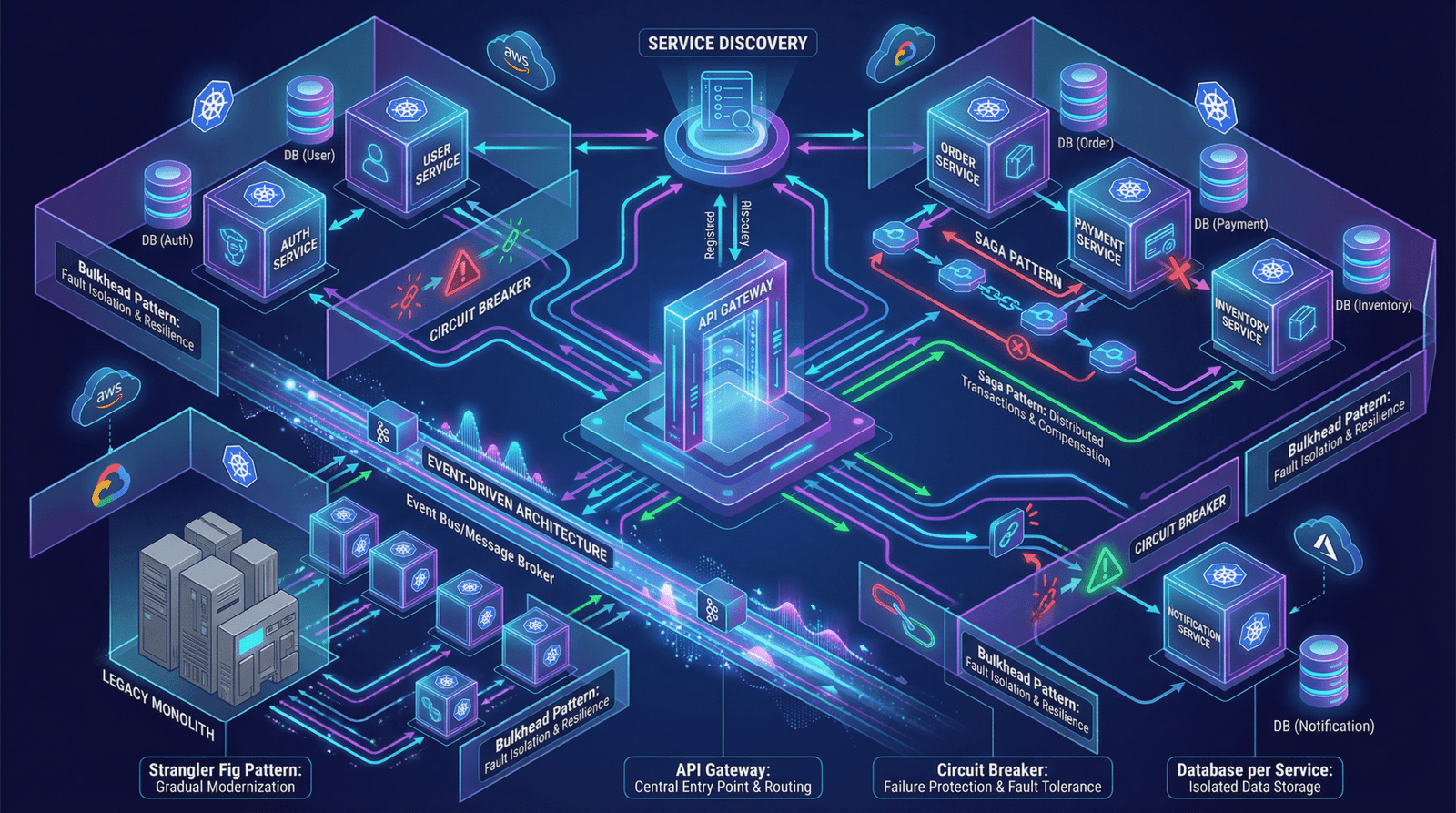

If microservices are the building blocks of modern software, design patterns are the blueprints that stop those blocks from collapsing under scale.
This pillar article is your one-stop, production-focused guide to Microservices Design Patterns — written for developers, architects, and DevOps engineers who want clarity, not chaos.
Whether you’re preparing for system design interviews, building cloud-native applications, or modernizing a legacy monolith, this guide will help you understand what pattern to use, when to use it, and why it matters.
What Are Microservices Design Patterns?
Microservices design patterns are proven architectural solutions to common challenges that arise when building distributed systems.
Unlike monolithic applications, microservices introduce complexities such as:
-
- Network latency
-
- Partial failures
-
- Data consistency
-
- Service communication
-
- Observability
-
- Deployment orchestration
Design patterns provide repeatable strategies to handle these problems without reinventing the wheel.
Why Microservices Patterns Matter in Real Projects
From real-world experience, teams that skip patterns often face:
-
- Cascading service failures
-
- Debugging nightmares
-
- Uncontrolled data duplication
-
- Tight coupling disguised as microservices
Teams that apply the right patterns early benefit from: ✅ Better scalability ✅ Faster releases ✅ Fault isolation ✅ Easier maintenance
Patterns don’t add complexity — they reduce it when used intentionally.
Core Categories of Microservices Design Patterns
This pillar guide groups patterns into six practical categories, the same way they appear in real systems.
1️⃣ Decomposition Patterns (Breaking the Monolith)
Instead of splitting by technical layers, services are built around business functions.
Example:
-
- Order Service
-
- Payment Service
-
- Inventory Service
Why it works:
-
- Aligns with domain ownership
-
- Enables independent scaling
🔹 Decompose by Subdomain (DDD-based)
Uses Domain-Driven Design (DDD) concepts to define bounded contexts.
Best for:
-
Large enterprises
-
Complex business rules
-
- Enables independent scaling
2️⃣ Communication Patterns (How Services Talk)
🔹 Service Discovery Pattern
Instead of hardcoding service locations, services dynamically discover each other.
Two types:
-
Client-side discovery (Netflix Eureka)
-
Server-side discovery (Kubernetes, AWS ALB)
Why it matters:
-
Enables auto-scaling
-
Removes single points of failure
👉 Internal Link: Service Discovery Pattern – Deep Dive
🔹 API Gateway Pattern
🔹 Backend for Frontend (BFF)
A single entry point for all clients.
Handles:
-
Authentication
-
Routing
-
Rate limiting
-
Response aggregation
Real-world insight: Without an API Gateway, frontend teams often end up tightly coupled to backend services.
👉 Internal Link: API Gateway Pattern – Deep Dive
Each client type gets its own tailored backend.
Example:
-
Web BFF
-
Mobile BFF
This avoids over-fetching and under-fetching problems.
👉 Internal Link: BFF Pattern – Deep Dive
3️⃣ Data Management Patterns (The Hardest Part)
🔹 Database per Service
Each microservice owns its private database.
Golden rule:
Never share databases between services.
Benefits:
-
Loose coupling
-
Independent scaling
👉 Internal Link: Database Per Service Pattern – Deep Dive
🔹 Saga Pattern
Manages distributed transactions without locking databases.
Types:
-
Choreography-based Saga
-
Orchestration-based Saga
Use case: E-commerce order placement across multiple services.
👉 Internal Link: Saga Pattern – Deep Dive
🔹 CQRS (Command Query Responsibility Segregation)
Separates read and write models.
Why teams love it:
-
Performance optimization
-
Clear responsibility separation
👉 Internal Link: Event Driven Architecture Pattern – Deep Dive
4️⃣ Reliability & Resilience Patterns
🔹 Circuit Breaker Pattern
Stops cascading failures by failing fast.
States:
-
Closed
-
Open
-
Half-open
Common tools: Resilience4j, Istio.
👉 Internal Link:Circuit Breaker Pattern – Deep Dive
🔹 Bulkhead Pattern
Isolates resources so failure in one service doesn’t impact others.
Think of it like watertight compartments in a ship.
👉 Internal Link:Bulkhead Pattern – Deep Dive
🔹 Retry & Timeout Pattern
Retries are useful — until they make things worse.
Best practice:
-
Combine retries with circuit breakers
-
Always use timeouts
5️⃣ Observability Patterns (Seeing the System)
🔹 Centralized Logging
Aggregate logs from all services into one place.
Tools: ELK Stack, OpenSearch
🔹 Distributed Tracing
Track a request across multiple services.
Tools: Zipkin, Jaeger
Personal insight: Once you use tracing in production, you’ll never go back.
🔹 Metrics & Monitoring
Measure:
-
Latency
-
Error rates
-
Throughput
Tools: Prometheus + Grafana
6️⃣ Deployment & Infrastructure Patterns
🔹 Blue-Green Deployment
Zero-downtime deployments using two environments.
🔹 Canary Release
Gradually roll out features to a subset of users.
Perfect for risk-free experimentation.
🔹 Sidecar Pattern
Attach auxiliary services like logging, security, or monitoring.
Common in service mesh architectures.
Common Mistakes Teams Make
❌ Adopting microservices too early
❌ Overusing synchronous communication
❌ Ignoring observability
❌ Treating patterns as rules, not guidelines
Frequently Asked Questions (FAQs)
Q1. Are microservices design patterns mandatory?
No, but skipping them often leads to scalability and reliability issues.
Q2. Which pattern should beginners start with?
Service Discovery, API Gateway, and Database per Service.
Q3. Are these patterns cloud-specific?
No. They apply to on-prem, cloud, and hybrid systems.
Q4. Can I use all patterns together?
No. Patterns must be chosen based on actual problems, not trends.
Final Thoughts
Microservices design patterns are experience captured in diagrams and principles.
Use them wisely, evolve them thoughtfully, and remember:
Good architecture doesn’t come from copying patterns — it comes from understanding them deeply.
Next in the Series:
-
Service Discovery Pattern (Deep Dive)
-
API Gateway vs BFF
-
Saga vs Two-Phase Commit
-
Observability for Microservices
Stay tuned 🚀

Leave a Reply