Service Discovery Pattern – Comprehending Microservices Design Patterns
Modern software systems are no longer monoliths running on a single server. They are dynamic, distributed, and constantly changing. In such environments, one of the biggest challenges is surprisingly simple:
How does one service find another service?
This is where the Service Discovery Pattern becomes a cornerstone of microservices architecture.
In this article, we’ll explore what service discovery is, why it exists, how it works, real-world implementations, tools, and best practices—all explained in a practical, human-friendly way.
Why Service Discovery Exists
In a traditional monolithic application:
Services run on fixed IPs
Endpoints rarely change
Configuration is static
In microservices:
Services scale up and down
Containers restart frequently
IP addresses change constantly
Multiple instances of the same service exist
Hardcoding service locations simply doesn’t work anymore.
👉 Service Discovery solves this problem by enabling services to dynamically locate each other at runtime.
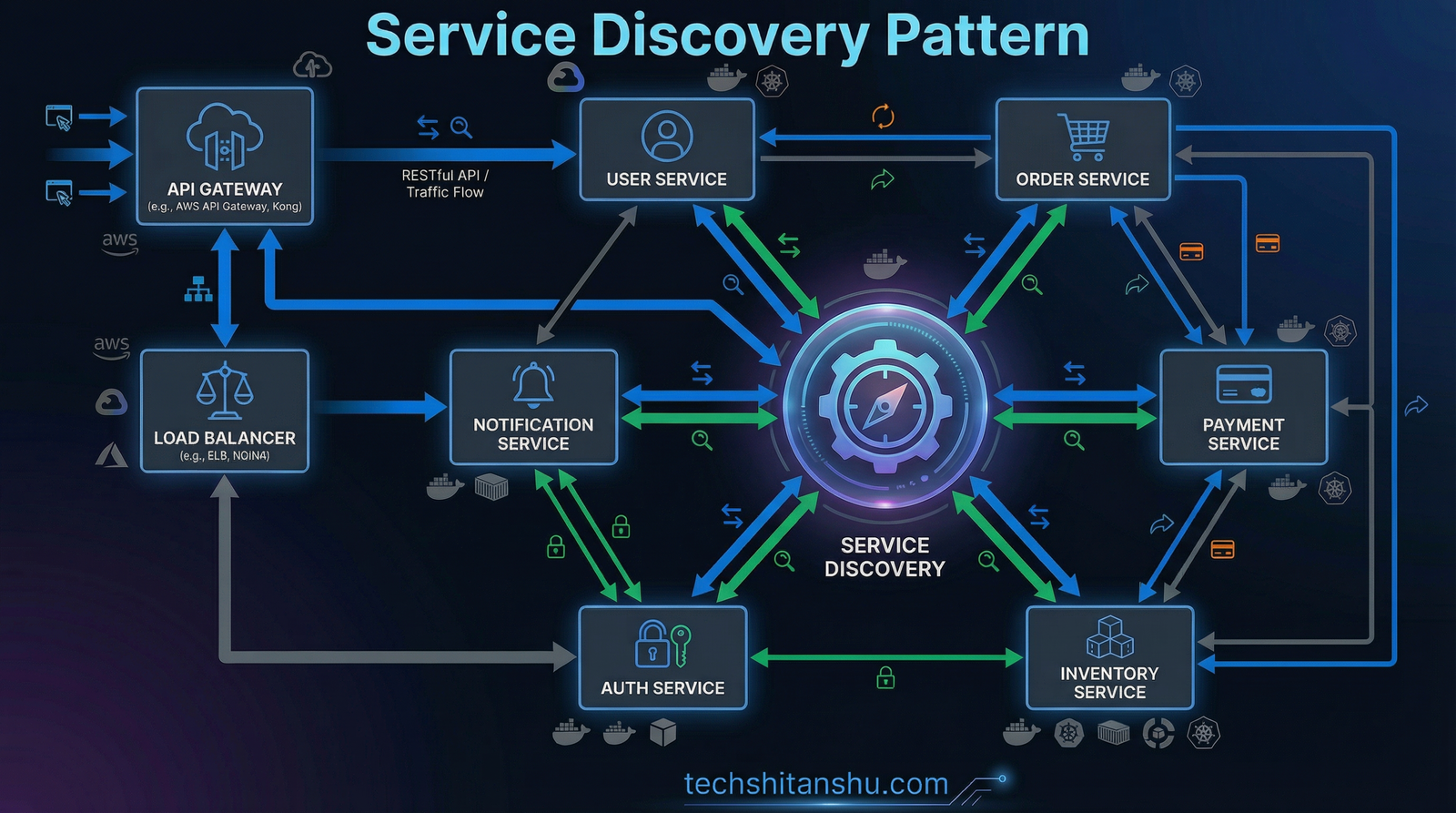
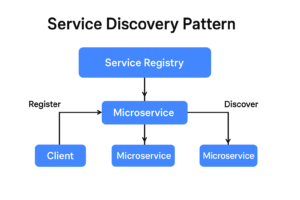
What Is the Service Discovery Pattern?
The Service Discovery Pattern allows microservices to:
Register themselves when they start
Discover other services dynamically
Route requests without hardcoded addresses
At its core, it introduces a Service Registry, a central directory that keeps track of:
Service names
Network locations
Health status
Instance metadata
Core Components of Service Discovery
1️⃣ Service Registry
A centralized database where services register themselves.
Examples:
Netflix Eureka
Consul
Zookeeper
Kubernetes API Server
2️⃣ Service Provider
A microservice that:
Registers itself with the registry
Sends heartbeat signals
Deregisters on shutdown
3️⃣ Service Consumer
A service that:
Queries the registry
Finds available service instances
Sends requests dynamically
Types of Service Discovery Patterns
1. Client-Side Service Discovery
In this model:
The client queries the service registry
The client chooses an instance
The client performs load balancing
Flow:
Service registers with registry
Client queries registry
Client selects instance
Client sends request
Tools:
Netflix Eureka
Spring Cloud LoadBalancer
Pros:
✔ No extra infrastructure
✔ Flexible client-side logic
Cons:
❌ Client complexity increases
❌ Language-specific libraries required
🟩 2. Server-Side Service Discovery
In this model:
Client sends request to a load balancer
Load balancer queries the registry
Load balancer routes the request
Flow:
Service registers
Client calls load balancer
Load balancer selects instance
Request is forwarded
Tools:
AWS ALB / NLB
Kubernetes Services
Istio / Envoy
Pros:
✔ Simple clients
✔ Centralized control
✔ Better security
Cons:
❌ Extra infrastructure layer
Client-Side vs Server-Side Discovery
| Feature | Client-Side | Server-Side |
|---|---|---|
| Complexity | Higher | Lower |
| Scalability | Good | Excellent |
| Cloud Native | Moderate | Strong |
| Operational Overhead | Medium | Low |
| Kubernetes Friendly | ❌ | ✅ |
Service Discovery in Kubernetes
Kubernetes offers built-in service discovery, making life much easier.
How Kubernetes Handles Discovery:
Each service gets a DNS name
Pods are discovered automatically
Load balancing is built-in
Example:
order-service.default.svc.cluster.local
This eliminates the need for external registries in many cases.
Service Discovery with API Gateway
In real systems, API Gateways often sit in front of microservices.
They:
Use service discovery internally
Hide service locations from clients
Add security, rate limiting, and logging
Popular Gateways:
Spring Cloud Gateway
Kong
NGINX
AWS API Gateway
Security Considerations
Service discovery must be secure.
Best practices:
Use mutual TLS (mTLS)
Restrict registry access
Encrypt service metadata
Monitor unauthorized registrations
Benefits of Service Discovery Pattern
✔ No hardcoded endpoints
✔ Automatic scaling support
✔ Improved fault tolerance
✔ Faster deployments
✔ Better system resilience
Common Mistakes to Avoid
Relying on static IPs
Ignoring health checks
Overloading the registry
No fallback strategy
Poor monitoring
Service Discovery vs Service Mesh
A Service Mesh (like Istio or Linkerd) builds on service discovery by adding:
Traffic management
Observability
Security
Retries & circuit breakers
Service discovery is the foundation, service mesh is the enhancement.
FAQs
What problem does service discovery solve?
It removes the need for hardcoded service locations in dynamic microservices environments.
Is service discovery mandatory in microservices?
Yes, for scalable and resilient systems.
Does Kubernetes need external service discovery?
Usually no, Kubernetes provides built-in discovery.
Which is better: client-side or server-side?
Server-side is preferred for cloud-native systems.
Is service discovery used in monoliths?
No, it’s mainly for distributed systems.
Final Thoughts
The Service Discovery Pattern is not optional anymore—it’s a foundational requirement for modern microservices architecture.
As systems grow larger and more dynamic, automatic discovery, resilience, and scalability become non-negotiable. Whether you’re using Spring Boot, Kubernetes, or a service mesh, mastering service discovery puts you one step closer to building truly cloud-native systems.

Leave a Reply