
Top 10 Popular Data Warehouse Tools
Architectures, Costs, When to Use (and When NOT to), + How to Choose
In a world driven by data-led decisions, picking the right data warehouse is a foundational architecture choice. Whether you’re powering business intelligence dashboards, machine learning models, or cross-system analytics, your choice impacts performance, cost, scalability, and ultimately business outcomes.
In this updated guide, we break down the top 10 data warehouse tools used by startups, mid-size, and enterprise teams — complete with:
- Architecture diagram prompts.
- Cost models explained.
- Situations to avoid each tool.
- A decision flowchart to help you choose faster

Table of Contents
What Is a Data Warehouse — A Quick Recap
A data warehouse is a centralized repository designed for analytics and reporting, storing historical data from multiple operational systems in a format optimized for queries and insight generation.
Unlike transactional systems, data warehouses are built for:
✔ Fast analytical queries
✔ Complex joins across domains
✔ Historical trend analysis
✔ Data integration from diverse sources
How to Use This Guide
Each section includes:
- Tool Overview
- Architecture Diagram
- Prompt
- Cost Model
- When NOT to Use It
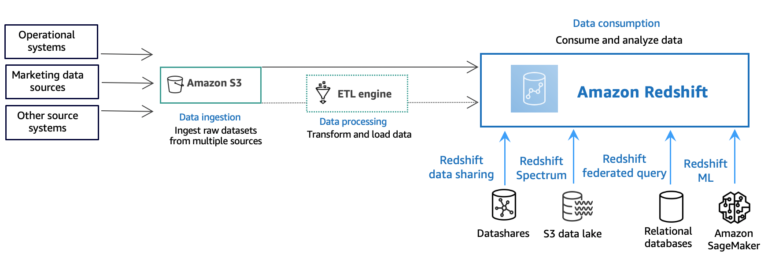
1️⃣ Amazon Redshift
Overview:
AWS’s flagship cloud data warehouse — fully managed, massively parallel processing (MPP), and deeply integrated with the AWS ecosystem.
Architecture Diagram Prompt
A high-level diagram showing Redshift clusters (compute + storage), data ingestion via AWS Glue and Kinesis, S3 as long-term storage, and BI tools like QuickSight querying through JDBC/ODBC. Include auto-scaling and concurrency scaling layers.
Cost Model
Pricing components:
Compute nodes: charged per hour
Storage: per GB/month
Data transfer: depending on region
Concurrency scaling: extra charges
Reserved instances: up to 75% off
Redshift Spectrum allows querying data directly on S3 (pay per TB scanned).
When NOT to Use
❌ You need real-time analytics — Redshift is strong for batch loads.
❌ You have unpredictable workload spikes without reserved planning — concurrency scaling can get expensive.
2️⃣ Google BigQuery
Overview:
A serverless, fully managed data warehouse with truly elastic scaling. BigQuery separates compute and storage, and charges mostly on data processed.
Architecture Diagram Prompt
Show BigQuery’s serverless model with separated storage and compute, data ingested via Dataflow/Cloud Pub/Sub, and dashboards like Looker accessing via BigQuery API.
Cost Model
Two main models:
✔ On-demand pricing: pay per TB scanned
✔ Flat-rate: predictable monthly compute
Storage: priced per GB monthly.
Streaming inserts: additional cost.
When NOT to Use
❌ You want predictable low-cost small workloads with minimal query volume — on-demand scanning charges may be high for small teams.
❌ You’re locked into non-Google ecosystems (complex connectors needed).
3️⃣ Snowflake
Overview:
A cloud-native, multi-cloud data warehouse that works across AWS, Azure, and GCP, with automatic scaling and workload isolation.
Architecture Diagram Prompt
Snowflake’s multi-cluster shared data architecture showing separate compute “virtual warehouses” accessing shared storage, with data loading via Snowpipe or external stages like S3/Azure Blob.
Cost Model
Two main parts:
Compute: charged in Snowflake “credits” per second
Storage: per TB per month
Credits vary by instance size. Auto-suspend and auto-resume help control costs.
When NOT to Use
❌ You have very tight per-query cost budgets — Snowflake can be expensive for ad-hoc analysts without credits monitoring.
❌ You want a self-hosted or on-prem option.
4️⃣ Microsoft Azure Synapse Analytics
Overview:
Unified analytics combining data warehousing and big data workloads (SQL pools + Spark). Synapse tightly integrates with Power BI.
Architecture Diagram Prompt
Azure Synapse architecture with dedicated SQL pools, serverless SQL pools, Apache Spark pools, pipelines from Azure Data Factory, and Power BI visualizing data.
Cost Model
Charges include:
Dedicated SQL pool: node/hour
Serverless SQL: pay per TB processed
Spark Pool: vCore/hour
Storage: per GB
When NOT to Use
❌ You don’t need tight Microsoft stack integration — other tools may be simpler.
❌ Your team isn’t ready for combined SQL + Spark complexity.
5️⃣ Apache Hive / Hadoop Data Warehouse
Overview:
Open-source warehousing on Hadoop. Traditional, schema-on-read solution often paired with HDFS and tools like Presto or Hive LLAP.
Architecture Diagram Prompt
A Hadoop data ecosystem with HDFS storage, Hive as querying layer, YARN resource manager, and clients running Presto/Impala for faster queries.
Cost Model
Costs are tied to infrastructure (VMs/servers), not managed billing. Storage + compute (VM hours) dominate.
When NOT to Use
❌ You need a fully managed cloud service — Hive requires operations overhead.
❌ You want fast ad-hoc queries without tuning.
6️⃣ Apache Druid
Overview:
Real-time analytics database optimized for OLAP queries on event streams — often used for dashboards with sub-second latency.
Architecture Diagram Prompt
Druid’s segment store with data ingested from Kafka/Stream, historical and real-time nodes, brokers, and clients querying dashboards.
Cost Model
Self-managed: compute + storage servers
Cloud managed (Imply Cloud): subscription
When NOT to Use
❌ Your workloads are classic batch ETL — traditional warehouses are better.
❌ You need ACID compliance across wide datasets.
7️⃣ ClickHouse
Overview:
Open-source MPP database for high-performance analytical queries (columnar storage).
Architecture Diagram Prompt
ClickHouse clusters with replicated shards, data replicated for fault tolerance, and query nodes serving OLAP dashboards.
Cost Model
Infrastructure cost (servers)
No managed billing unless using hosted providers
When NOT to Use
❌ You require deep integration with BI features (ClickHouse is raw query engine).
❌ Your team isn’t comfortable self-managing cluster ops.
8️⃣ IBM Db2 Warehouse
Overview:
On-prem/cloud data warehouse with strong enterprise features and governance.
Architecture Diagram Prompt
IBM Db2 Warehouse with storage nodes, compute nodes, connectors to ETL tools, and enterprise security layers.
Cost Model
Subscription/license
Hardware/VMs or IBM Cloud billing
When NOT to Use
❌ You prioritize cloud-native serverless features.
❌ You don’t need heavy enterprise compliance.
9️⃣ Oracle Autonomous Data Warehouse
Overview:
Fully managed Oracle cloud warehouse with auto-tuning and strong SQL features.
Architecture Diagram Prompt
Oracle ADW with autonomous optimizer, data ingestion via Oracle Data Integrator, and BI tools querying via standard SQL.
Cost Model
OCPU/hour
Storage per GB/month
Networking charges
When NOT to Use
❌ You want cost-effective small workloads — Oracle’s pricing may be high.
❌ You don’t use Oracle ecosystem.
🔟 Teradata Vantage
Overview:
Enterprise-grade hybrid warehouse supporting analytics at scale.
Architecture Diagram Prompt
Teradata nodes with workload management, hybrid cloud deployment, connectors to ETL platforms, and BI tools.
Cost Model
Subscription + compute/storage licensing
Hardware or cloud billing depending on deployment
When NOT to Use
❌ You’re a small team with limited budgets — Teradata is enterprise-focused.
Decision Flowchart — Which Warehouse Should You Choose?
Use this simplified flow to pick a tool:
Start
├── Do you want serverless without ops?
│ ├── Yes → BigQuery or Snowflake
│ └── No
│ ├── Are you deeply AWS? → Redshift
│ ├── Azure stack? → Synapse
│ ├── Need real-time analytics? → Druid
│ └── Open-source preferred?
│ ├── High performance SQL → ClickHouse
│ ├── Hadoop ecosystem → Hive
│ └── Enterprise governance → Db2 / Teradata
Cost Models — What to Expect
| Tool | Pricing Type | Best for Cost Control |
|---|---|---|
| BigQuery | On demand / flat rate | Good transparency |
| Snowflake | Credits | Auto-suspend for savings |
| Redshift | On-demand + reserved | Reserved helps |
| Synapse | vCore + storage | Mix workloads |
| ClickHouse | Infra cost | Self-tune |
| Hive | Infra cost | Long-term big data |
| Druid | Infra + subscription | Real-time focus |
| Oracle ADW | OCPU | Enterprise SLAs |
| Db2 | License | Enterprise governance |
| Teradata | License | Hybrid/enterprise |
Choosing for Your Use Case
Startups
BigQuery – low ops, pay per use
Snowflake – easy scaling
ClickHouse – high performance analytics
Avoid: Hive (too heavy ops), Teradata (too expensive)
Enterprise
Redshift – mature AWS stack
Synapse – Microsoft enterprises
Oracle ADW / Teradata – regulated, large data
Avoid: On-prem only (if cloud is strategy)
Dev / Test
BigQuery On demand
Snowflake trial tiers
ClickHouse local setup
Avoid: Heavy enterprise warehouses until needed
Final Thoughts
No single data warehouse fits all needs.
Your choice should balance:
✔ Cost
✔ Scalability
✔ Ops overhead
✔ Integration ecosystem
✔ Performance needs
This structured comparison — with architecture prompts, cost modeling, and use cases — should help you make a confident decision in 2025.
Frequently Asked Questions (FAQs)
❓ What is a data warehouse used for?
A data warehouse is used to store, combine, and analyze large volumes of historical data from multiple systems. It helps businesses run complex queries, generate reports, track trends, and make data-driven decisions without impacting live production systems.
❓ What is the difference between a database and a data warehouse?
A traditional database is designed for day-to-day transactions (inserts, updates, deletes).
A data warehouse is optimized for analytics and reporting, handling large read-heavy queries across historical datasets.
In short:
Database = operational work
Data warehouse = analytical insights
❓ Which data warehouse is best for startups?
For startups, the best choices are:
Google BigQuery (serverless, pay-as-you-go)
Snowflake (easy scaling, minimal operations)
ClickHouse (high performance with lower infrastructure cost)
Startups should avoid heavy enterprise platforms early to keep costs and complexity low.
❓ Which data warehouse is best for enterprise use?
Enterprises typically prefer:
Amazon Redshift (AWS ecosystem)
Azure Synapse Analytics (Microsoft stack)
Snowflake (multi-cloud, workload isolation)
Teradata or Oracle ADW (regulated industries)
These platforms offer better governance, security, and scalability.
❓ Is Snowflake better than BigQuery?
It depends on your use case:
BigQuery is ideal if you want serverless analytics with minimal setup and are okay with pay-per-query pricing.
Snowflake is better if you need predictable performance, workload isolation, and multi-cloud support.
There is no universal “better” — only better for your workload.
❓ When should you NOT use a cloud data warehouse?
Avoid cloud data warehouses if:
Your data volumes are extremely small
You only need simple reports
Your organization has strict on-prem-only requirements
You don’t have a clear analytics use case
In such cases, a traditional database or BI tool may be enough.
❓ Are open-source data warehouses production-ready?
Yes, tools like ClickHouse, Apache Hive, and Apache Druid are production-ready — but they require:
Strong DevOps skills
Monitoring and tuning
Cluster management expertise
Managed cloud warehouses are often easier for small teams.
❓ How much does a data warehouse cost per month?
Typical cost ranges (rough estimate):
Startups: $50 – $500/month
Mid-size teams: $500 – $5,000/month
Enterprise: $10,000+/month
Costs depend on data size, query volume, compute usage, and architecture choices.
❓ What is the most cost-effective data warehouse?
BigQuery for unpredictable workloads
Snowflake with auto-suspend enabled
ClickHouse for high-performance analytics with self-managed infrastructure
Cost efficiency depends more on how you use the tool than the tool itself.
❓ Can data warehouses handle real-time analytics?
Some can, but not all.
Apache Druid and ClickHouse are excellent for near real-time analytics
Redshift, Snowflake, BigQuery are better suited for batch or micro-batch workloads
Choose based on latency requirements.
❓ How do I choose the right data warehouse?
Ask these questions:
How big is my data?
Do I need real-time or batch analytics?
What cloud ecosystem am I already using?
How much operational overhead can my team handle?
Do I need strict governance or compliance?
Your answers will naturally point to the right tool.

Leave a Reply